Cet article est une synthèse et une introduction d’un cours que nous donnons dans des formations de niveau Master 2 et Grandes Écoles. Il s’appuie aussi sur notre expérience sur notre expérience professionnelle (15+ projets industriels et hospitaliers sur données réelles) et académique sur le sujet (Encadrement de thèses par Vincent Augusto) :
– Martin Prodel (2014-2017)
prédiction du parcours patient à partir du PMSI
– Hugo De Oliveira (2017-2020)
modélisation prédictive des parcours du SNDS
– Jules Le Lay (2019-2022)
optimisation des parcours de soins de patients multimorbides
– Laura Uhl (2020-2024)
prédiction de parcours de soins intra hospitalier
Les articles scientifiques associés sont en référence à la fin de l’article 👇.
Lorsque l’on parle du fonctionnement réel d’un hôpital, d’un bloc opératoire ou d’un parcours de patients chroniques, on s’appuie souvent sur des procédures, des protocoles ou des schémas de flux. Pourtant, toute personne ayant travaillé sur l’étude des parcours de soins en pratique sait que la réalité ne suit jamais parfaitement ces modèles.
Il existe une différence entre ce qui devrait se passer et ce qui se passe réellement.
C’est précisément dans cet espace que se situe une discipline scientifique qui mériterait selon nous d’être encore plus connue : le Process Mining.
Cet article est conçu comme un mini tuto de découverte, destiné à celles et ceux qui souhaitent comprendre cette méthode, son origine, ses principes fondamentaux et surtout sa valeur concrète dans les organisations de santé.
Bienvenue dans cette introduction guidée au Process Mining.
1. Définition : que signifie “Process Mining” ?
Le terme anglais Process Mining est généralement traduit en français par “fouille de processus” ou “analyse des processus à partir des données”. Cette traduction, bien que correcte, peut laisser penser à une simple extraction de données ou à un audit documentaire. En réalité, le Process Mining est une discipline scientifique à part entière, située à la croisée de trois domaines :
- l’informatique,
- la théorie des processus,
- et l’analyse des traces numériques.
L’idée fondatrice est simple mais élégante:
À chaque fois qu’un système informatique enregistre un événement, il capture une partie de l’histoire réelle d’un processus. Le Process Mining reconstitue cette histoire.
Ainsi, plutôt que de s’appuyer sur la manière dont un processus est censé fonctionner, il montre la manière dont il fonctionne réellement, au travers de milliers d’événements enregistrés dans les systèmes d’information.
2. Une discipline née à l’université, mais conçue pour le terrain
Le Process Mining démarre dans des travaux académiques des années 1990-2000, menés notamment à l’université de technologie d’Eindhoven (Pays-Bas), autour du professeur Wil van der Aalst, aujourd’hui considéré comme “le père fondateur” de la discipline.
À l’origine, ces travaux cherchaient à combiner deux mondes :
- les modèles de workflow (Rigoureux, théoriques, utilisés pour décrire des processus)
- et les données d’exécution réelles (Désordonnées, imparfaites, issues de systèmes métiers)
Le Process Mining est né là : un moyen de comparer la théorie et la pratique, la norme et le vécu, le modèle et la donnée brute.
Depuis, c’est devenu un champ scientifique à part entière, avec ses méthodes, ses algorithmes, ses outils, ses revues, ses conférences, ses communautés, et des centaines de publications. Par exemple, j’obtiens 2 477 résultats pour une recherche d’articles sur IEEE explore, entre 2015 et 2025 avec le mot clé “process mining”; et 311 pour la même chose sur Pubmed (en date du 28 novembre 2025).
Pour nous, son intérêt dépasse la recherche : il s’agit d’un outil utile pour analyser et transformer les organisations de santé, où les processus sont complexes, multi professionnels, hétérogènes et chargés de variabilité.
3. Les trois piliers du Process Mining (sans simplifier à l’excès)
Dans un cadre d’enseignement, nous présentons toujours le Process Mining via trois grandes familles d’analyses, qui forment sa colonne vertébrale :
A. La découverte de processus (« process discovery »)
Il s’agit de reconstruire automatiquement la structure du processus à partir des données. L’algorithme ne connaît rien du processus ; il le redécouvre en analysant les enchaînements réels d’événements. C’est souvent une révélation pour les organisations : ce qu’elles imaginaient n’a rien à voir avec ce que montrent les données.
💡(pour aller plus loin sur le process discovery) Derrière le concept : une problématique de reconstruction de graphes
En termes formels, on cherche à :
reconstituer un graphe orienté G = (N, E) où
→ N = activités observées
→ E = transitions possibles
→ à partir d’un ensemble de traces T = {σ₁, σ₂, …, σₙ}
→ où chaque trace σᵢ est une séquence ordonnée d’événements :
σᵢ = (a₁ → a₂ → … → aₖ).Le défi théorique est qu’il existe une infinité de graphes possibles capables de reproduire les traces données. Le Process Mining cherche donc une solution minimale, générale et fidèle aux données, en optimisant un compromis entre 4 critères :
- fitness (le modèle doit pouvoir reproduire les traces observées)
- précision (il ne doit pas autoriser trop de comportements non observés)
- généralisation (il doit être robuste aux variations futures)
- simplicité (principe d’Ockham)
Les algorithmes emblématiques
Alpha Miner (le premier historiquement)
Basé sur des relations de causalité simples (→, ||, ↔), il reconstruit le modèle en interprétant les co-occurrences temporelles. Ses limites : bruit, boucles courtes, complexité réelle.
Heuristic Miner (simple et efficace)
Introduit un scoring probabiliste : on estime la force des relations en fonction des fréquences, ce qui permet de réduire l’impact des événements rares ou anormaux.
Inductive Miner (l’état de l’art pour les projets industriels)
Il reconstruit le processus sous forme d’un arbre de blocs structurés (séquence, choix, boucle, parallèle), ce qui garantit :
– absence d’ambiguïté
– modèles toujours structurés et compréhensibles
– scalabilité pour des millions d’événements.
C’est ce dernier algorithme (et ses variantes) que nous enseignons et que nous utilisons fréquemment dans nos projets industriels, en particulier lorsque les logs sont hétérogènes, incomplets ou très volumineux.
Toutes ces méthodes sont facilement disponibles en Python via PM4PY (Open Source)
PM4Py est une bibliothèque open-source en Python dédiée au Process Mining : en d’autres termes, elle offre un ensemble complet d’algorithmes et d’outils permettant de reconstruire, analyser, visualiser et améliorer des processus réels à partir de journaux d’événements.

B. La vérification de conformité (conformance checking)
Pour ce deuxième pilier, on compare le processus réel avec le processus attendu ou théorique. On mesure les écarts, leur fréquence, leurs impacts.
Dans les hôpitaux, c’est souvent là que l’on découvre des étapes sautées, des retours en arrière, des séquences trop longues, des ruptures, ou des variations entre équipes…
💡(pour aller plus loin sur la conformance checking) La vision mathématique derrière : un problème d’alignement optimal
Le Conformance Checking cherche à comparer :
- un modèle théorique de parcours (par exemple exprimé en réseau de Petri)
versus
- un ensemble de traces réelles T (par exemple les parcours de 150 000 patients)
en produisant un alignement optimal entre les deux.
En théorie, on cherche une solution du problème :
>>> “minimiser Σ coûts(moves entre théorie et réalité)
>>> sous contrainte de reproduire entièrement la trace (= la réalité).”
Il s’agit d’un problème combinatoire complexe, souvent résolu par :
- des variantes de l’A*
- des méthodes heuristiques
- des approximations via contraintes linéairesC. L’analyse de performance
C’est le volet le plus opérationnel : durées, temps d’attente, goulots d’étranglement, variabilité. En santé, cette dimension permet d’identifier précisément où et pour qui les patients attendent trop.
Ces trois piliers donnent au Process Mining une puissance en tant qu’outil : il peut décrire, comparer, quantifier — le tout en s’ancrant dans les trajectoires réelles.
💡 (Pour aller plus loin sur l’analyse de perfomances) Les concepts mathématiques sous-jacents
1. Analyses statistiques (classiques) des distributions, car Les temps ne sont jamais gaussiens.
2. Identification des goulots d'étranglement : théorème de la file d’attente
3. Analyse des parcours variants
Mathématiquement, on peut mesurer la complexité d’un processus par :
- l’entropie de Shannon (mesure de variabilité des chemins),
- le nombre de variantes distinctes (souvent > 500 dans les urgences),
- l’entropie conditionnelle (variabilité selon un sous-groupe).4. De la théorie à la pratique : ce que nous observons dans les projets
Nos étudiants découvrent souvent les résultats de leurs premières analyses avec une forme d’étonnement :
« Je ne pensais pas que les processus étaient aussi variés »
« Je ne m’attendais pas à voir autant de chemins différents »
« Je ne savais pas que ce service était un goulot d’étranglement »
Cet étonnement, nous le retrouvons également dans les projets industriels. Voici trois situations typiques, anonymisées, issues de notre expérience :
Exemple 1 : Parcours chirurgical
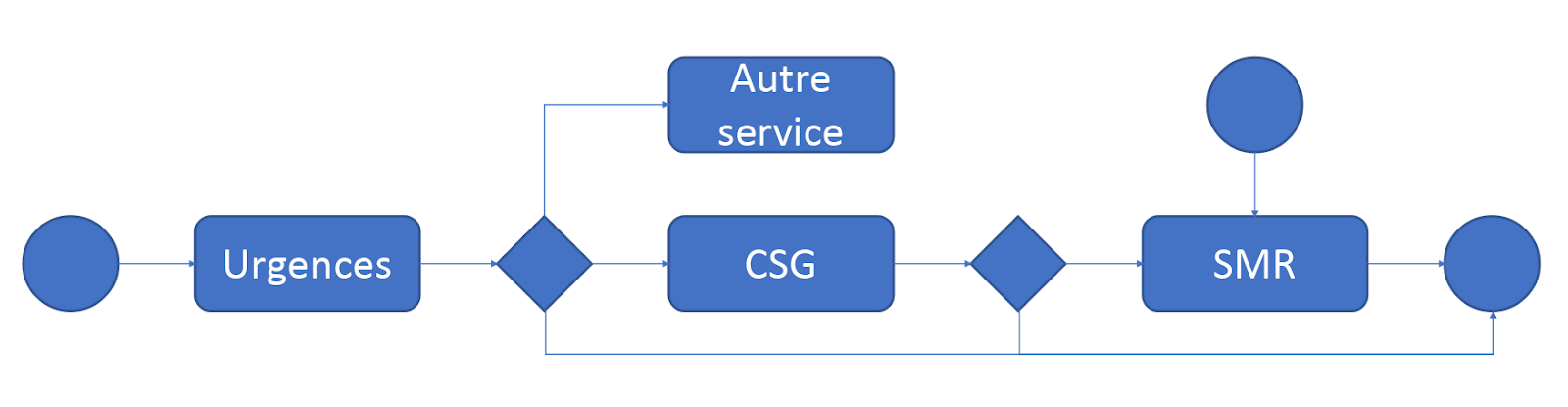
Dans un projet mené en chirurgie, la reconstruction automatique des parcours a révélé trois “routines” très différentes selon les jours de la semaine. Certaines séquences pré-opératoires étaient effectuées de manière tardive les lundis, créant un allongement de délai très significatif. Ce n’était écrit nulle part ; seule l’analyse des traces l’a mis en lumière.
Exemple 2 : Service d’urgences
Un flux inattendu apparaissait systématiquement dans les graphes : un groupe de patients contournait un point de passage pourtant considéré comme “obligatoire” dans la procédure. Il s’agissait en réalité d’une organisation informelle mise en place pour résoudre un problème local… des années plus tôt.
Exemple 3 : Parcours de maladies chroniques
Le Process Mining a permis d’identifier des ruptures de suivi invisibles dans les dashboards classiques. Certains patients s’échappaient du parcours avant de revenir plus tard pour des complications. L’équipe clinique savait que le suivi était imparfait ; elle ne connaissait ni l’ampleur ni le profil des patients concernés.
Dans chacun de ces cas, la force du Process Mining tient au fait qu’il montre, avec une neutralité scientifique, ce que la donnée raconte.
5. Pourquoi le Process Mining est particulièrement pertinent en santé
Dans les systèmes industriels (manufacturing, supply chain), les processus sont souvent linéaires, fortement automatisés, et optimisés depuis longtemps.
Dans la santé, l’humain est central, la variabilité est naturelle, et les contraintes sont multiples.
C’est pourquoi le Process Mining y apporte de la valeur :
- il objective ce qui est habituellement discuté sur la base d’impressions,
- il met en lumière les pratiques réelles plutôt que les intentions,
- il révèle des micro-adaptations locales, qui deviennent parfois des macro-problèmes,
- il aide à structurer des décisions d’organisation fondées sur des résultats quantifiés.
Pour un directeur d’hôpital, un chef de service ou un cadre de pôle, il offre un nouveau type de miroir : un miroir objectif de l’activité. Pour un responsable sur une aire thérapeutique ou pour un produit de santé, il pose une base objective pour travailler sur les parcours.
6. Au-delà du diagnostic : Process Mining, simulation et jumeaux numériques
L’analyse par Process Mining constitue souvent la première étape d’un travail de transformation organisationnelle. Chez DALI, nous la combinons systématiquement avec la modélisation, la simulation et les jumeaux numériques organisationnels.

Le Process Mining sert alors à ancrer le modèle dans la réalité :
→ il fournit la structure des parcours, les distributions de temps, la variabilité observée.
La simulation permet ensuite de tester des scénarios : réorganisations, changement de planning, ajout de ressources, modification de séquences.
C’est ce lien “analyse du réel + expérimentation virtuelle” qui rend nos projets particulièrement pertinents pour les hôpitaux et les industriels. Ils sont alors “Utiles”, “Utilisables” et “Utilisés”.
Conclusion : le Process Mining, entre science et terrain
Le Process Mining est devenu, en quelques années, un outil incontournable pour comprendre les organisations complexes. Il combine la rigueur de la recherche, la finesse de l’analyse des données et la pertinence du diagnostic opérationnel.
Ce que nous apprécions le plus, en tant qu’enseignants et praticiens, c’est sa capacité à réconcilier la théorie et la réalité. Il montre ce qui est, et non ce que l’on imagine.
Il aide à mieux comprendre, donc à mieux agir.
Dans les organisations de santé, cette compréhension est un levier essentiel pour améliorer les parcours, réduire les délais, optimiser les ressources et, in fine, améliorer l’expérience des patients et des professionnels.
Si vous souhaitez aller plus loin, ou si vous envisagez de former vos équipes à cette méthode, nous serions ravis de partager notre expertise, à la fois académique et opérationnelle : contact@dali.science
Nos articles scientifiques publiés sur le sujet depuis 10 ans
- Le Lay J.; Augusto V.; Alfonso-Lizarazo E.; Masmoudi M.; Gramont B.; Xie X.; Bongue B.; Celarier T. COVID-19, Bed Management Using a Two-Step Process Mining and Discrete-Event Simulation Approach (2024) IEEE Transactions on Automation Science and Engineering 21:3:3080-3091 doi:10.1109/TASE.2023.327484
- Le Lay J.; Perrier L.; Augusto V.; Boucher X.; Xie X., Modelling and Simulation of Genomic Sequencing Platform Operations (2023) Proceedings – Winter Simulation Conference ::1160-1171 doi:10.1109/WSC60868.2023.1040766
- Le Lay J.; Neveu J.; Dalmas B.; Augusto V., Automated generation of patient population for discrete-event simulation using process mining (2022) Simulation Series 54:1:803-814 doi: 10.23919/ANNSIM55834.2022.9859406
- Uhl L.; Augusto V.; Dalmas B.; Alexandre Y.; Bercelli P.; Jardinaud F.; Aloui S., Evaluating the Bias in Hospital Data: Automatic Preprocessing of Patient Pathways Algorithm Development and Validation Study (2024) JMIR Medical Informatics 12::- doi: 10.2196/58978
- Uhl L.; Augusto V.; Lemaire V.; Alexandre Y.; Jardinaud F.; Bercelli P.; Aloui S., Progressive prediction of hospitalisation and patient disposition in the emergency department (2022) Proceedings – 2022 IEEE International Conference on Big Data, Big Data 2022 ::1719-1728 doi: 10.1109/BigData55660.2022.10020777
- De Oliveira H.; Augusto V.; Jouaneton B.; Lamarsalle L.; Prodel M.; Xie X., Automatic and explainable labeling of medical event logs with autoencoding (2020) IEEE Journal of Biomedical and Health Informatics 24:11:3076-3084 doi:10.1109/JBHI.2020.3021790
- De Oliveira H.; Augusto V.; Jouaneton B.; Lamarsalle L.; Prodel M.; Xie X., Optimal process mining of timed event logs (2020) Information Sciences 528::58-78 doi: https://doi.org/10.1016/j.ins.2020.04.020
- Prodel M.; Augusto V.; Jouaneton B.; Lamarsalle L.; Xie X. Optimal Process Mining for Large and Complex Event Logs (2018) IEEE Transactions on Automation Science and Engineering 15:3:1309-1325 doi: 10.1109/TASE.2017.2784436
- Prodel M.; Augusto V.; Xie X.; Jouaneton B.; Lamarsalle L., Stochastic simulation of clinical pathways from raw health databases (2017) IEEE International Conference on Automation Science and Engineering 2017-August::580-585 doi: 10.1109/COASE.2017.8256167
Augusto V.; Xie X.; Prodel M.; Jouaneton B.; Lamarsalle L., Evaluation of discovered clinical pathways using process mining and joint agent-based discrete-event simulation (2016) Proceedings – Winter Simulation Conference 0::2135-2146 doi: 10.1109/WSC.2016.7822256